Abstract
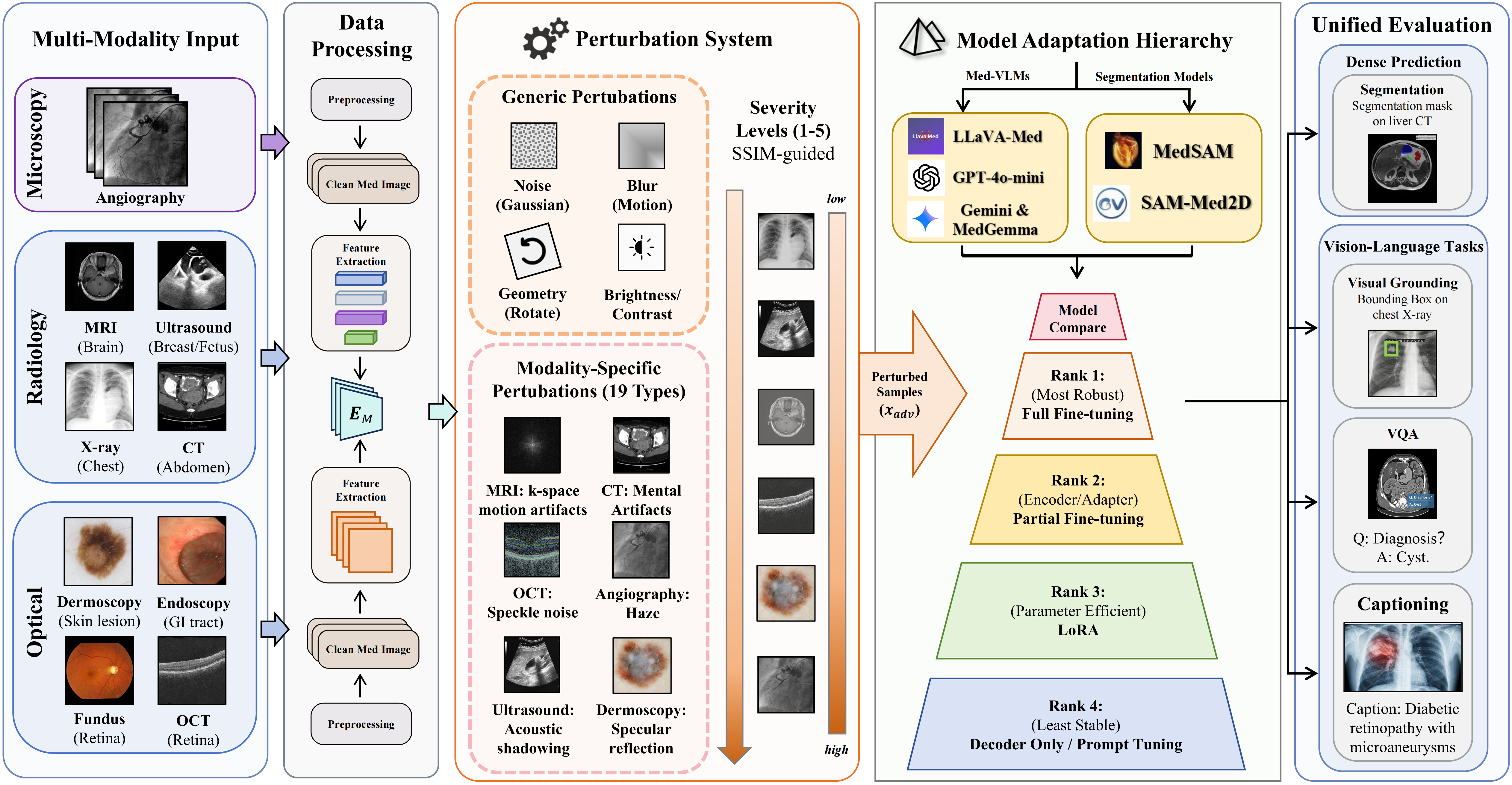
Medical foundation models have achieved remarkable clinical performance, yet their robustness under real-world perturbations remains underexplored. We present a robustness benchmark comprising 40 perturbation types (12 base, 28 medical-specific) across eight imaging modalities, evaluating five VLMs (LLaVA-Med, MedGemma, MedGemma-1.5, Gemini-2.5-flash and GPT-4o-mini) on VQA, visual grounding, and captioning, alongside two segmentation models (MedSAM, SAM-Med2D) with five fine-tuning strategies.
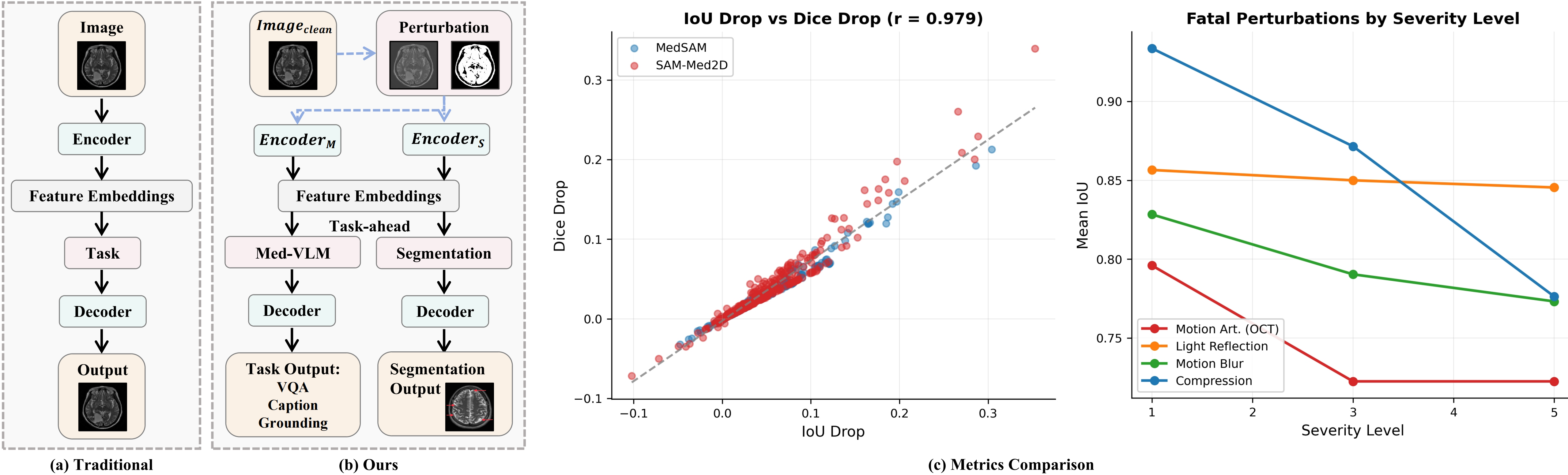
Our findings reveal: (1) Fine-tuning strategy dominates robustness, with LoRA exhibiting nearly double the degradation of full fine-tuning, while SAM-Med2D's Adapter offers favorable efficiency–robustness trade-off. (2) Medical-specific perturbations disproportionately damage segmentation, with 9 of 15 top corruptions being domain-specific. (3) LoRA-tuned visual grounding drops over 40 points, whereas zero-shot captioning remains stable (<7% drop). These results provide deployment guidelines and underscore the necessity of domain-specific robustness evaluation for medical AI.
Key Findings
Fine-tuning strategy dominates robustness. LoRA exhibits ≈2× the degradation of full fine-tuning. SAM-Med2D's Adapter is the best PEFT efficiency–robustness trade-off.
Medical-specific corruptions are disproportionately harmful. 9 of top 15 perturbations are domain-specific — standard benchmarks underestimate real deployment risks.
Task formulation determines VLM robustness. LoRA-tuned Grounding drops >40 points, while zero-shot Captioning stays stable (<7% drop).
General VLMs excel at VQA but fail on Grounding. Gemini-2.5-flash: 54% relative drop. Medical VLMs are more stable; MedGemma shows the smallest drops overall.
Results
Comprehensive evaluation across segmentation and VLMs under 40 perturbation types at 5 severity levels.
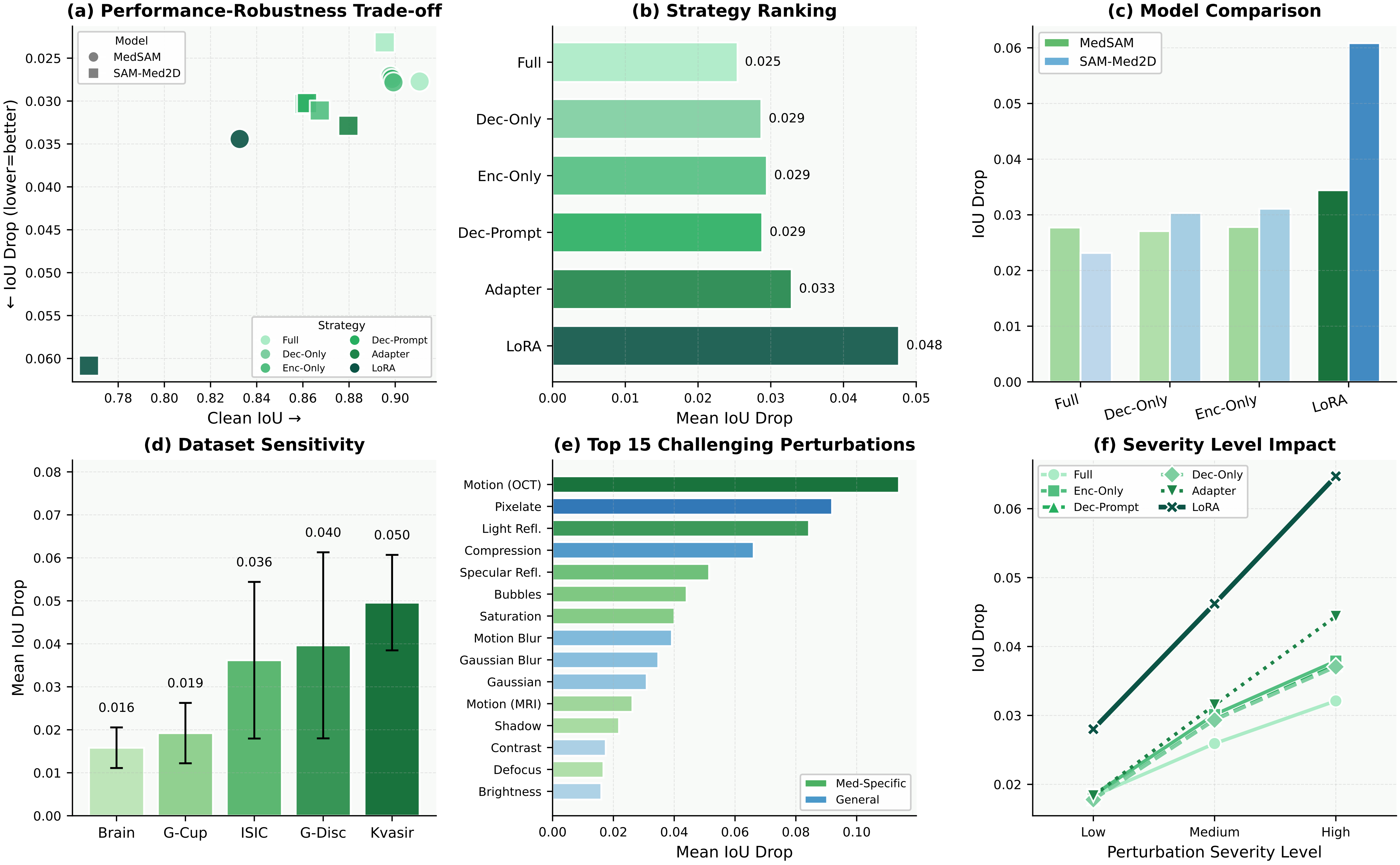
Segmentation — Strategy Ranking
| Rank | Strategy | IoU Drop |
|---|---|---|
| 1 | Full fine-tuning | 0.025 |
| 2 | Dec-Only | 0.029 |
| 2 | Enc-Partial | 0.029 |
| 2 | Dec-Prompt | 0.029 |
| 5 | Adapter | 0.033 |
| 6 | LoRA | 0.048 (≈2×) |
VLM — Task Robustness
| Task | Setting | Drop |
|---|---|---|
| Captioning | Zero-shot | <0.02 BLEU |
| VQA (med.) | Zero-shot | <8 pts |
| VQA (Gemini) | Zero-shot | 36.1 pts (54%) |
| Grounding | LoRA FT | >40 pts |
Benchmark Coverage
Perturbation Types (40 total)
- Base (12): Gaussian/salt-pepper/speckle noise, Gaussian/motion blur, brightness, contrast, JPEG, pixelation, rotation, scaling, translation
- Med-Specific (28): CT metal artifacts, MRI ghosting & bias-field, US acoustic shadowing, pathology stain variations, endoscopy bubbles & specular reflections, OCT shadow/blink/defocus, X-ray scatter & exposure, angiography haze
Datasets & Models
- Segmentation: ISIC 2016, Brain Tumor MRI, Glaucoma Disc/Cup, Kvasir-SEG
- VLM: OmniMedVQA, ROCOv2, MeCoVQA
- Seg Models: MedSAM, SAM-Med2D
- VLMs: LLaVA-Med, MedGemma, MedGemma-1.5, GPT-4o-mini, Gemini-2.5-flash
BibTeX
@inproceedings{anonymous2026medfmrobust, title = {MedFM-Robust: Benchmarking Robustness of Medical Foundation Models}, author = {Anonymous}, booktitle = {Medical Image Computing and Computer Assisted Intervention (MICCAI)}, year = {2026}, note = {Under Review} }